
Anthropic has launched Claude Fable 5 for general use and Claude Mythos 5 for restricted trusted-access partners. Here is what changed, what the benchmarks show, how safeguards work, what it costs, and what users and businesses should check before adopting it.
Last checked: June 9, 2026. This article uses Anthropic's June 9 launch post as the primary source, and checks availability, pricing, data-retention, fallback and API details against Anthropic's Claude API documentation, Claude Help Center, Anthropic's Mythos model page, Anthropic's risk report, Axios, The Verge and Business Insider. Benchmark results are Anthropic-reported unless stated otherwise.
Quick answer
Anthropic launched Claude Fable 5 on June 9, 2026, calling it the most capable model it has ever made generally available. The company also launched Claude Mythos 5, a restricted version of the same underlying model for vetted cybersecurity and, soon, biology research partners.
The important distinction is access and safeguards:
- Claude Fable 5 is the public model. It is available through Claude API and major cloud platforms, but it includes safety classifiers that route some higher-risk cybersecurity, biology, chemistry and model-distillation requests away from Fable.
- Claude Mythos 5 is not generally available. It is initially limited to approved Project Glasswing partners and trusted-access customers, with some safeguards lifted for defensive or research use.
- Both models are priced at $10 per million input tokens and $50 per million output tokens.
- Both support a 1 million token context window and up to 128,000 output tokens per request, according to Anthropic's API docs.
- Claude Fable 5 and Mythos 5 require 30-day data retention and are not available under zero data retention on the Claude API.
Anthropic says Fable 5 leads nearly all of its tested benchmarks and is strongest on long, complex tasks such as agentic coding, knowledge work, scientific reasoning, vision and long-context work. Those benchmark claims are vendor-reported, so teams should validate the model on their own workloads before making purchasing or architecture decisions.
What happened
Anthropic announced Claude Fable 5 and Claude Mythos 5 as the next stage of its Mythos-class model line. The launch is significant because Anthropic had previously kept Mythos-class capabilities behind restricted access, mainly through Project Glasswing, because of their cybersecurity and biology risk profile.
Fable 5 is Anthropic's attempt to make Mythos-level capability broadly useful without making every capability broadly accessible. Instead of releasing the unrestricted model to everyone, Anthropic wrapped the public version in classifiers and fallback behavior.
The company says these safeguards are deliberately conservative at launch. In practice, that means users may see some legitimate security or science requests handled by Claude Opus 4.8 instead of Fable 5. Anthropic says more than 95% of Fable sessions do not trigger fallback, but the company also says false positives are expected while safeguards are refined.
Fable 5 vs Mythos 5
The easiest way to understand the launch is to treat Fable and Mythos as two access modes for similar capability.
| Question | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Who can use it? | General users and developers, subject to plan and platform availability. | Approved Project Glasswing and trusted-access partners. |
| Is it generally available? | Yes, beginning June 9, 2026. | No. It is limited availability only. |
| Underlying model | Same underlying model family as Mythos 5, according to Anthropic. | Same underlying model as Fable 5, with some safeguards lifted. |
| Risk controls | Safety classifiers and fallback for high-risk categories. | Restricted access, trusted partner review and 30-day retention. |
| API model ID | claude-fable-5 | claude-mythos-5 |
| Context window | 1M tokens | 1M tokens |
| Max output | 128k tokens | 128k tokens |
| Pricing | $10 input / $50 output per million tokens | $10 input / $50 output per million tokens |
| Zero data retention | Not available on Claude API. | Not available on Claude API. |
Anthropic says Mythos 5 will first upgrade users who already had access to Claude Mythos Preview, including Project Glasswing partners. The company says it plans to expand trusted access over time, but Axios reported that there is no clear timeline for a broader program.
Benchmark snapshot
Anthropic's published benchmark table shows Fable 5 and Mythos 5 ahead of Claude Opus 4.8, Claude Mythos Preview, GPT 5.5 and Gemini 3.1 Pro on most listed tasks. The table also notes that for some cybersecurity and biology-related benchmarks, Claude Fable 5 performs closer to Opus 4.8 because Fable's safeguards route those requests away from the full model.

Selected Anthropic-reported results include:
| Benchmark | Claude Fable 5 / Mythos 5 | Claude Opus 4.8 | GPT 5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
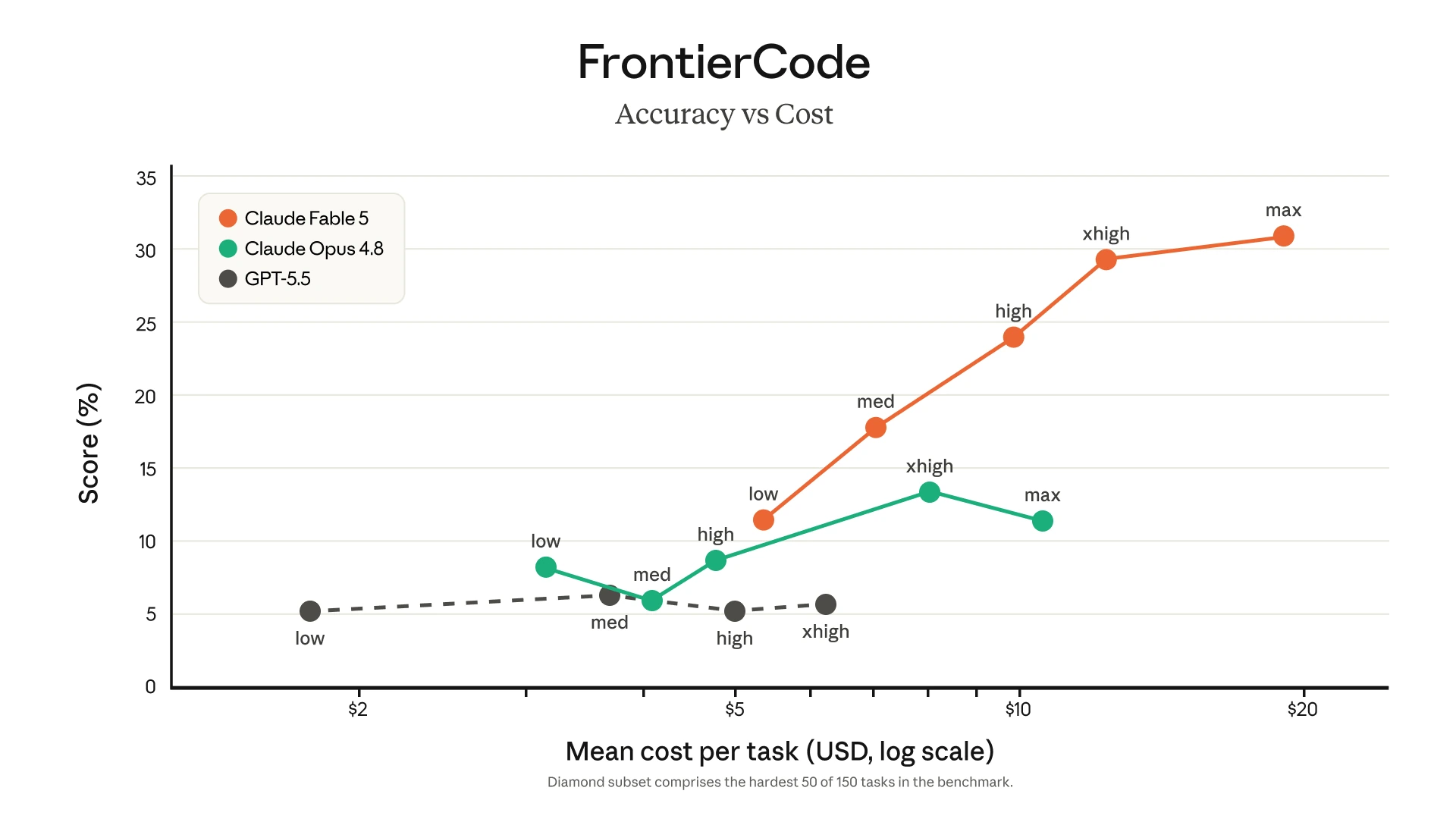
| FrontierCode Diamond | 29.3% | 13.4% | 5.7% | Not listed |
| GDPval-AA | 1932 | 1890 | 1769 | 1314 |
| GDP.pdf vision | 29.8% | 22.5% | 24.9% | 16.7% |
| Blueprint-Bench 2 | 38.6% | 14.5% | 36.2% | 26.5% |
| AutomationBench | 17.4% | 15.5% | 12.9% | 9.6% |
| OSWorld-Verified | 85.0% | 83.4% | 78.7% | 76.2% |
| Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% |
| Terminal-Bench 2.1 | 88.0% | 82.7% | 83.4% | 70.7% |
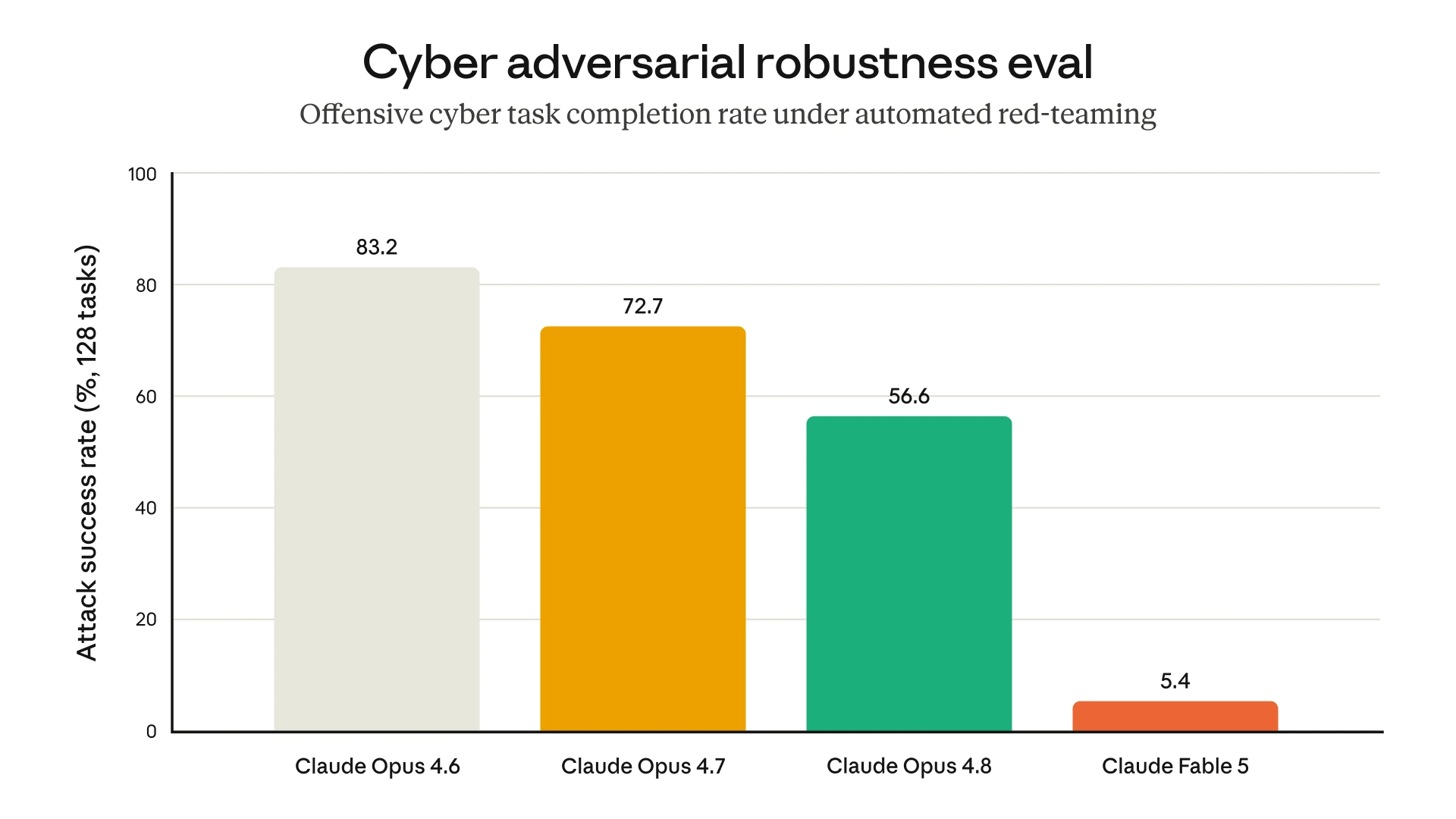
| ExploitBench Cap% | 78.0% | 40.0% | 34.0% | Not listed |
| HealthBench Professional | 66.0% | 56.9% | 51.8% | Not listed |
This is useful directional evidence, not a deployment guarantee. Benchmarks can be sensitive to test design, harnesses, tool access, effort settings, refusal behavior and the exact model snapshot tested. Businesses should run their own evaluation set with real documents, tickets, code, dashboards, policy rules and edge cases.
Why the software-engineering claims matter
Anthropic is presenting Fable 5 as a long-horizon agentic coding model, not just a chat model that writes short snippets. The strongest claims are about complex migrations, production-quality changes and autonomous work across large codebases.
The official launch post says Stripe tested Fable 5 on a 50-million-line Ruby codebase and saw the model complete a broad migration in a day that would otherwise have taken a large team far longer. That is an early customer example, not an independent benchmark, but it explains why Anthropic is emphasizing long tasks and codebase-scale work.
The cost story matters too. Anthropic argues Fable 5 is more expensive per token than Opus 4.8 but can be cheaper per completed hard task if it needs fewer retries, fewer prompts and less human scaffolding. That can be true for difficult agentic work and false for routine work. A simple summarization, classification or support macro may still be better served by Sonnet or Haiku-tier models.

For developers, the right question is not only "which model scores highest?" It is:
- Can it finish the task without going off track?
- Does it create tests or only code?
- Does it preserve local architecture and conventions?
- Does it reduce review time or increase reviewer burden?
- Does it respect repo security rules, secrets handling and deployment constraints?
- What is the cost per merged, tested, production-safe change?
Agentic coding results
Anthropic's agentic coding visual highlights two separate benchmarks: SWE-Bench Pro and FrontierCode. Fable 5 is shown ahead of Claude Opus 4.8 and GPT 5.5 on both.
For product teams, this reinforces a practical split:
| Use case | What to test before adopting Fable 5 |
|---|---|
| Code migrations | Can it update many files while preserving tests, build behavior and style rules? |
| Bug fixing | Does it reproduce the bug, add a regression test and avoid overbroad changes? |
| Legacy modernization | Does it understand hidden coupling and deployment constraints? |
| Security review | Does it explain impact and mitigation without producing unsafe exploit detail? |
| Data engineering | Does it preserve schema compatibility and failure handling? |
| Agent workflows | Can it stop, ask for missing context and recover from tool errors? |
The model may be a strong fit for hard engineering work, but the release does not remove the need for code review, tests, CI, staging and human sign-off.
Knowledge work, vision and long-context tasks
Anthropic says Fable 5 improves complex analytical work, document reasoning, chart and table interpretation, spatial reasoning and visual tasks. The company also says the model stays focused over millions of tokens in long-running tasks and can use notes to improve later outputs.
The 1M-token context window is important for legal, financial, research, policy and engineering workflows because it can hold more source material at once. But long context is not the same as perfect memory. Teams should still structure prompts, use retrieval, cite sources, check outputs and keep high-impact decisions under review.
Good early tests include:
- Asking the model to reconcile conflicting numbers across filings, memos or spreadsheets.
- Testing whether it cites exact source passages for every material claim.
- Feeding it a long incident timeline and checking whether it preserves chronology.
- Giving it UI screenshots and asking for implementation plans.
- Asking it to update a policy while preserving legal definitions.
- Testing whether the answer changes when irrelevant documents are added to context.
Life sciences and drug-design claims
The most sensitive part of the launch is biology. Anthropic says internal protein-design experts used Mythos 5 to accelerate parts of drug-design work by around ten times. The company also says nine of 14 studied protein targets produced strong candidates now under investigation.

This is not a sign that consumer Claude users now have unrestricted biology design capabilities. Anthropic says Fable 5 routes many biology and chemistry requests to Opus 4.8. Mythos 5 access for biology is planned for a small trusted-access group of researchers and life-science organizations.
The public-interest upside is real: faster hypothesis generation, therapeutic target exploration and scientific reasoning. The risk is also real: advanced models can lower barriers for dangerous dual-use work. That is why biology and chemistry appear in the model's safety-classifier coverage.
How Fable 5 safeguards work
Anthropic's public model uses separate classifiers to identify requests in categories where Mythos-level capabilities could increase risk. The launch materials name three main areas:
- Cybersecurity.
- Biology and chemistry.
- Model distillation.
When the classifiers detect covered high-risk requests, the public Fable 5 experience falls back to Claude Opus 4.8 instead of letting Fable answer directly. Anthropic says users will be informed when that happens.

For developers using the API, refusals are not treated as HTTP errors. Anthropic's docs say a Fable 5 refusal can return a successful HTTP 200 response with stop_reason: "refusal" and classifier details. Developers can handle fallback themselves or use Anthropic's fallback mechanisms where available.
That difference matters for product design. A Fable-powered workflow should not assume every model response is a normal answer. It needs states for:
- Normal completion.
- Refusal.
- Fallback completion from another model.
- User-visible explanation.
- Logging and safety monitoring.
- Billing and retry handling.
Jailbreak and misalignment testing
Anthropic says it ran internal and external testing before launch. The company says an external bug bounty produced no universal jailbreaks after more than 1,000 hours of testing, though it also acknowledges that completely eliminating universal jailbreaks may not be possible.
The company also published a misalignment assessment chart showing Mythos 5 close to Opus 4.8 and lower than Sonnet 4.6 on the reported metric. Anthropic says Fable 5 should be similar because the underlying model is the same, though the public model has additional safeguards.
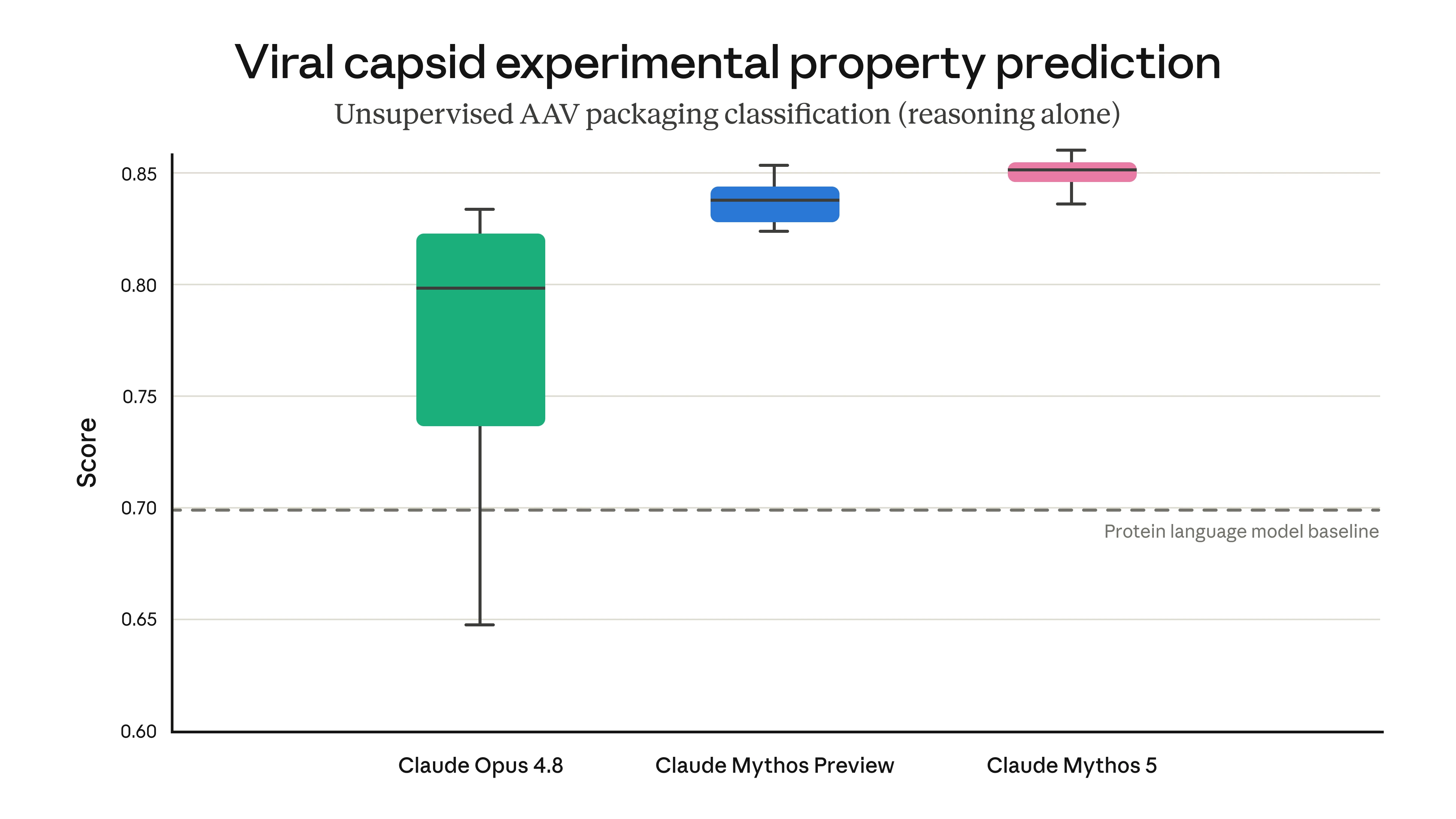
The responsible reading is cautious. A low misalignment score on Anthropic's automated assessment does not mean there is no risk. It means Anthropic's published testing did not show a higher overall level of misaligned behavior than the comparison models on that assessment. Real-world deployment still depends on monitoring, access controls, prompt design, human review and incident response.
Availability and plan changes
Anthropic says Claude Fable 5 is available beginning June 9, 2026 through:
- Claude API.
- Claude Platform on AWS.
- Amazon Bedrock.
- Google Cloud Vertex AI.
- Microsoft Foundry.
For subscription users, Anthropic announced a staged rollout:
| Dates | What Anthropic says |
|---|---|
| June 9 through June 22, 2026 | Fable 5 is included on Pro, Max, Team and seat-based Enterprise plans at no extra cost. |
| June 23, 2026 onward | Fable 5 is removed from those included plan pools unless Anthropic extends the window. Continued use requires usage credits. |
| Later, when capacity allows | Anthropic says it aims to restore Fable 5 as a standard part of subscription plans. |
Usage credits are billed separately from a paid Claude subscription and use standard API pricing rates after included usage limits are reached, according to Claude Help Center documentation.
Pricing and cost planning
Fable 5 is priced above Opus 4.8:
| Model | Input price | Output price |
|---|---|---|
| Claude Fable 5 | $10 per million tokens | $50 per million tokens |
| Claude Mythos 5 | $10 per million tokens | $50 per million tokens |
| Claude Opus 4.8 | $5 per million tokens | $25 per million tokens |
| Claude Sonnet 4.6 | $3 per million tokens | $15 per million tokens |
| Claude Haiku 4.5 | $1 per million tokens | $5 per million tokens |
That pricing makes Fable 5 a premium model. It may be rational for high-value workflows such as major code migrations, executive analysis, legal review, frontier research or complex data tasks. It is probably inefficient for routine work that a cheaper model can complete reliably.
For buyers, cost should be measured per accepted result, not per token alone:
| Metric | Why it matters |
|---|---|
| Cost per completed task | Captures retries, review and failed attempts. |
| Human review minutes saved | Measures real productivity, not just model quality. |
| Error correction cost | A strong model can still be expensive if mistakes are costly. |
| Fallback rate | Classifier-triggered fallback can affect quality and latency. |
| Context size | 1M-token workflows can become expensive quickly. |
| Output length | 128k outputs can drive cost if not controlled. |
Data retention and compliance
This is one of the most important adoption details. Anthropic's API documentation says Claude Fable 5 and Claude Mythos 5 are designated covered models and require 30-day data retention. Zero data retention is not available for either model on the Claude API.
Anthropic says retained data is not used to train new Claude models without permission, but the 30-day requirement still matters for regulated companies and sensitive workloads.
Before using Fable 5 with confidential data, organizations should check:
- Whether their contract permits 30-day retention.
- Whether their data classification policy allows the workflow.
- Whether the platform is first-party Claude API, Bedrock, Vertex AI or Microsoft Foundry, because retention rules can differ by platform.
- Whether HIPAA, financial, legal or government restrictions apply.
- Whether prompts include customer secrets, source code, credentials, logs, employee data or protected health information.
- Whether fallback behavior routes the request through an allowed model and platform.
For some teams, Fable 5 will be a high-value model used only in controlled environments. For others, the retention requirement may rule out certain workloads until contracts, platform controls or internal policies are updated.
What users should do now
Individual Claude users should treat Fable 5 as a premium model for hard tasks:
- Use it for complex coding, long documents, difficult reasoning, visual analysis and multi-step planning.
- Keep routine drafts, short summaries and simple edits on lower-cost models when available.
- Watch for messages that indicate fallback to Opus 4.8.
- Do not paste sensitive personal, legal, health or employer data unless your account and organization allow it.
- Expect access and plan rules to change after June 22.
If you are using Fable 5 through a paid subscription, check your usage credit settings before June 23 so you do not accidentally create unexpected pay-as-you-go charges.
What developers should change
Developers integrating Fable 5 should update systems for three things: cost, fallback and retention.
| Area | Practical change |
|---|---|
| Model ID | Use claude-fable-5 for the public model. Use claude-mythos-5 only if your organization has limited access. |
| Refusals | Handle stop_reason: "refusal" as a valid response state, not an outage. |
| Fallback | Decide whether to retry automatically, ask the user, or route to a cheaper model. |
| Billing | Track prompt, output, cache and fallback costs separately. |
| Context | Do not fill 1M tokens by default; design retrieval and compaction carefully. |
| Output | Set output budgets so 128k-token responses do not become uncontrolled costs. |
| Data retention | Confirm whether your organization can use covered models with 30-day retention. |
| Monitoring | Log fallback rates, refusal categories, latency and accepted-output quality. |
The model also uses adaptive thinking by default, and Anthropic says raw chain-of-thought content is never returned. If your app depends on visible reasoning traces, use summarized thinking where supported and avoid building UI expectations around hidden internal reasoning.
What businesses should evaluate
Fable 5 should not be adopted just because it is the newest frontier model. A serious evaluation should compare it against Opus, Sonnet, Gemini, GPT and internal baselines on tasks the business actually performs.
Useful evaluation tracks:
- Coding: bug fixes, migrations, test generation, repo-specific conventions.
- Research: source-grounded answers, citations, contradiction handling.
- Legal: redlines, clause extraction, risk summaries.
- Finance: spreadsheet reasoning, variance analysis, chart interpretation.
- Operations: policy comparison, customer cases, incident timelines.
- Security: defensive triage summaries and patch planning without unsafe exploit detail.
- Vision: screenshots, charts, scientific figures and UI reconstruction.
Set pass/fail thresholds before testing. Otherwise, teams often mistake impressive demos for production reliability.
What is confirmed and what is not
| Claim | Status |
|---|---|
| Anthropic launched Claude Fable 5 and Claude Mythos 5 on June 9, 2026. | Confirmed by Anthropic. |
| Fable 5 is Anthropic's most capable widely released model. | Confirmed as Anthropic's claim and in API docs. |
| Mythos 5 is the same underlying model with safeguards lifted in some areas. | Confirmed by Anthropic. |
| Fable 5 is available through Claude API and major cloud platforms. | Confirmed by Anthropic docs. |
| Mythos 5 is generally available. | Not true. It is limited availability. |
| Fable 5 and Mythos 5 have a 1M token context window and 128k max output. | Confirmed by Anthropic docs. |
| Fable 5 and Mythos 5 are available under zero data retention. | Not true on Claude API. Anthropic says 30-day retention is required. |
| Fable 5 is the best public AI model in the world. | Not independently proven. Anthropic reports leading benchmark performance; independent testing is needed. |
| Fable 5 removes the need for human review. | Not supported. Human review remains necessary for high-impact work. |
Open questions
Several issues need more time and independent testing:
- How often Fable 5 falls back to Opus 4.8 in real enterprise workflows.
- Whether harmless security and science work is routed away too often.
- How Fable 5 performs in independent coding and research benchmarks.
- Whether 1M-token workflows remain reliable under noisy context.
- Whether the cost per successful task beats cheaper models.
- How quickly Anthropic can expand trusted Mythos access without increasing misuse risk.
- Whether cloud-platform data retention and governance rules will be simple enough for regulated customers.
- Whether competing labs respond with similar safeguarded public models.
Bottom line
Claude Fable 5 is Anthropic's most important public model release since the company introduced Mythos-class capabilities. It gives general users access to a stronger model while keeping some of the riskiest capabilities behind classifiers, fallback behavior and trusted access.
That tradeoff is the story. Fable 5 is not just a better chatbot. It is a test of whether frontier AI companies can safely commercialize models that are powerful enough to help with major software, science and knowledge work, but also powerful enough to raise cybersecurity and biology concerns.
For users, it is worth trying on genuinely difficult tasks. For developers, it requires fallback-aware integration. For businesses, it requires cost, retention, compliance and safety review before sensitive deployment.
FAQ
Is Claude Fable 5 available to everyone?
Claude Fable 5 is generally available beginning June 9, 2026 through the Claude API and supported cloud platforms, with staged access on Claude subscription plans. Actual availability can still depend on region, account, plan, capacity and platform.
Is Claude Mythos 5 public?
No. Claude Mythos 5 is limited to approved customers, including Project Glasswing partners. It is not a self-serve public model.
Are Fable 5 and Mythos 5 the same model?
Anthropic says they share the same underlying model. Fable 5 is the public safeguarded version. Mythos 5 is the restricted version with some safeguards lifted for approved use cases.
What does Fable 5 cost?
The API price is $10 per million input tokens and $50 per million output tokens. Subscription-plan access is included only through June 22, 2026 unless Anthropic extends the window; after June 23, use may require usage credits.
Does Fable 5 support zero data retention?
No, not on the Claude API. Anthropic's documentation says Fable 5 and Mythos 5 require 30-day data retention and are not available under zero data retention.
Can Fable 5 help with cybersecurity?
It may help with general defensive security analysis, but Anthropic says high-risk cybersecurity requests can trigger fallback to Opus 4.8. Mythos 5 access for more sensitive defensive work is limited to approved partners.
Should a business replace all Claude usage with Fable 5?
No. Fable 5 is a premium model. Use it where higher capability changes outcomes. Keep lower-cost models for routine tasks, and validate the model on internal benchmarks before wide rollout.
Sources
- Anthropic: Claude Fable 5 and Claude Mythos 5, June 9, 2026.
- Claude API Docs: Introducing Claude Fable 5 and Claude Mythos 5.
- Claude API Docs: Models overview.
- Claude API Docs: Pricing.
- Claude API Docs: API and data retention.
- Claude Help Center: Manage usage credits for paid Claude plans.
- Anthropic: Claude Mythos model page.
- Anthropic: Claude Fable 5 and Claude Mythos 5 system card PDF.
- Anthropic risk report PDF, updated May 26, 2026.
- The Verge: Anthropic releases its first Mythos-class model Claude Fable, June 9, 2026.
- Axios: Anthropic releases Mythos-level model for general use, June 9, 2026.
- Business Insider: Anthropic releases Claude Fable 5, a Mythos-class AI model with safeguards, June 9, 2026.
Media credits
The launch visuals and benchmark charts in this article are Anthropic media assets from the official Claude Fable 5 and Claude Mythos 5 announcement, downloaded and served locally by HacksByte for news reporting context.
Before you move on
Global AI workflow guidance. Use this short checklist to turn the article into action.
- Check whether the tool can access private files or account data.
- Verify factual claims against primary sources before publishing.
- Keep a human review step for work that affects money, school, or customers.
This guide is written for practical user safety. For account, platform, or legal decisions, confirm critical steps with the official help center or your service provider.


