Generative AI has enabled human level comprehension and reasoning in software—a fundamental innovation that will touch every industry and many of the products we use today. However, as our team continues to meet with companies and founders building AI products and features, we’ve found that they are running into a common set of hurdles that can slow development, or in some cases, block it all together.
Examining past technology adoption cycles reveals this to be a fairly common pattern—a disruptive technology introduces a new paradigm, but also introduces new challenges that must be solved for the technology to reach its full potential and adoption.
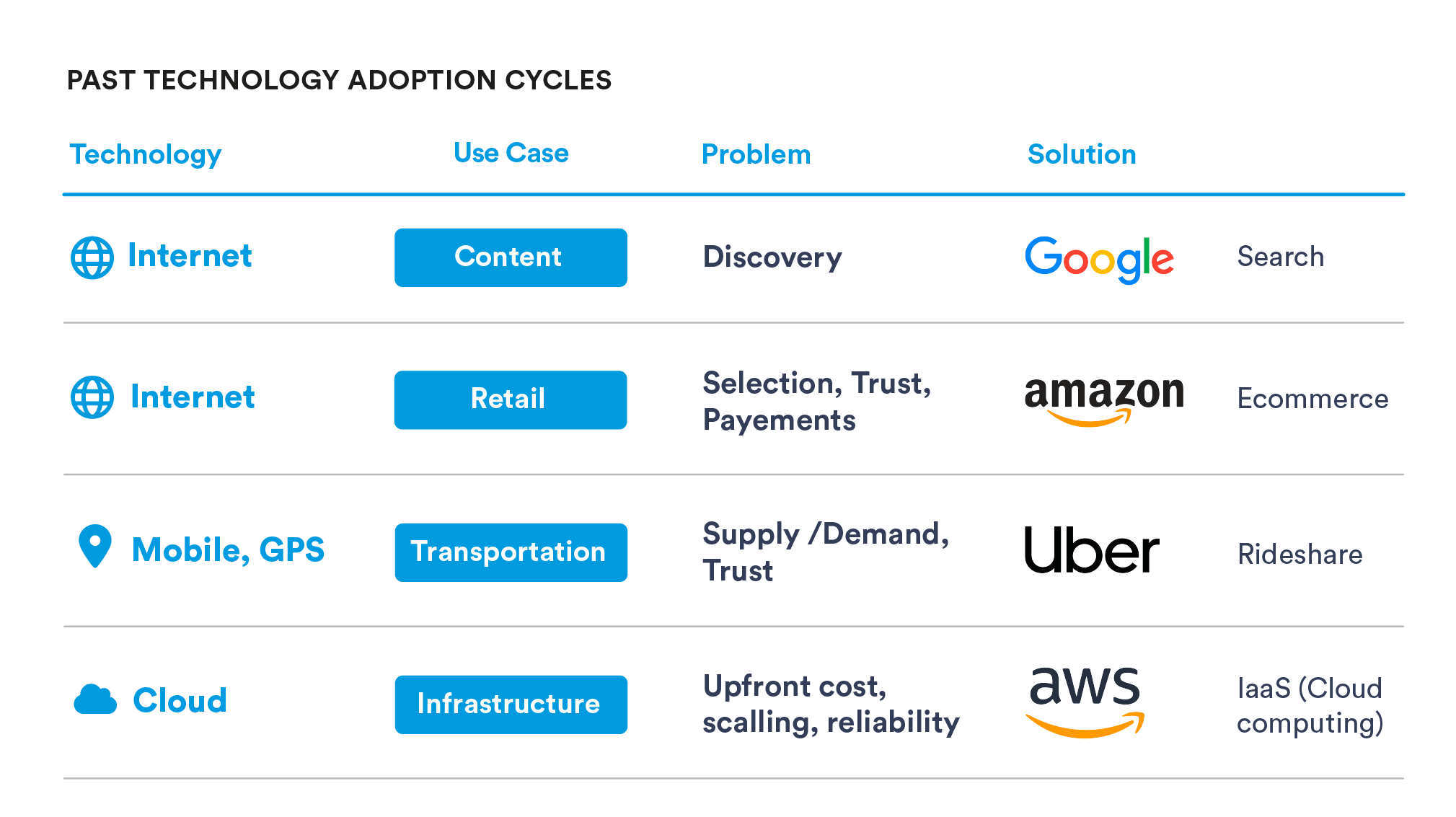
Companies that solve hard problems tend to be the ones that benefit the most when new technologies rearrange value chains.
As we look towards the emerging platform shift brought on by new AI technologies, the “hard problem” framework can be a useful tool in identifying where we will see the next wave of innovation, and possibly, the next billion dollar businesses being built.
Section 1 — What are the problems?
Relevance: bigger is not necessarily better
Foundational models are, as the name might imply, platforms on which a wide array of applications can be built. Models achieve this breadth by training on huge datasets and encoding that knowledge across billions of parameters. It may seem a logical conclusion that the bigger the model, the better its performance, but this isn’t always the case. The underlying quality, quantity, and relevance of a model’s training data heavily affect its output, as well as whether or not its developers chose to use additional alignment techniques.
One example that illustrates why unaugmented foundational models can be suboptimal choices for founders and businesses developing AI applications is InstructGPT by OpenAI. As a general language model trained to predict internet text, GPT-3 by itself struggled to follow user instructions when asked to act as an assistant. To counter this problem, OpenAI created a fine-tuned version of GPT-3 called InstructGPT, designed to engage in user-assistant style dialogue. The resulting model had 100x fewer parameters, but was cheaper to run and performed better for the application specific use case of being an assistant. This innovation ultimately became the model that powers chatGPT, which has amassed over 100 million users precisely because it performs so well in the conversational setting it was specialized for.
If OpenAI decided—based on cost and task performance—that its state-of-the-art GPT-3 model wasn’t a fit for its chatbot use case, it’s likely that many business users will come to similar conclusions and pursue model alignment through fine-tuning, prompt engineering, or training and deploying their own smaller models. These decisions carry added development costs and complexity that not all organizations are well equipped to meet.
LLMs are information and action constrained
LLMs are trained on large, but ultimately static, datasets. While a model can be retrained on a cadence, its built-in factual knowledge can only ever include the data that was used to train it. As a result, LLM output can be stale and unknowledgeable of private information about the end user. Furthermore, since LLMs only output text, they can’t themselves take actions a user might desire. For a model to do anything besides inference over its built-in knowledge set requires additional development to link the LLM to outside systems.
Retrieving external data like a customer’s purchase history or taking action like booking a reservation, requires additional agents, permissions, and data infrastructure that the foundational model can interact with and query against.
LLMs are expensive
Developing a high quality foundational model requires a significant outlay of capital, resources, and time. Even still, model development typically isn’t the most expensive aspect of putting AI into production. A majority of a model’s costs are incurred in inference, which is an unbounded function of its popularity and usage. As a result, products that leverage LLMs—whether internally built or through an API with passed along costs—typically have higher marginal costs and latency than traditional software. This has implications for how developers think about feature tradeoffs, scalability, and business model.
In instances where human led work is substantially slower and more expensive than the AI alternative, AI products have achieved very attractive unit economics. However, free-to-use AI products and features have needed to institute throttling and blackouts to control burn and maintain performance. For LLMs to evolve from prompt-based automations for high cost human work to always-on elements of a new generation of software, cost and latency will need to come down through continued optimization and innovation across the LLM stack.
LLMs are not always private
Many LLMs are made available as services through an API. That means that these models are developed, hosted, and run by an external party. To leverage these models in products, developers must send data in prompts to the model owners who then must be trusted to handle it appropriately. If data is not handled appropriately or adequate privacy policies are not in place, information passed to a model can end up in its training dataset and, theoretically, be leaked inadvertently to other users. As a result, privacy has become a major consideration for companies looking to leverage LLMs over internal data or customer data and has resulted in companies banning or limiting the use of popular applications.
To get around these issues, companies must establish and trust data policies with LLM providers, receive permission from customers to share information, or simply host their own models. While potentially solvable, privacy challenges currently undermine much of the convenience and expertise advantages gained by outsourcing model development and hosting to third parties.
LLMs can be unreliable
LLMs can produce plausible content in a variety of situations, but there is no guarantee that the output is correct. A widely syndicated example was chatGPT’s failure to play valid chess moves when asked. There are a range of niche problems where LLMs need to adhere to logical schemes that they may be unfamiliar with and where the mistakes are not comical but costly. LLMs are well known to lie, to guess rather than to ask for clarification from users, and to give toxic output. Bridging the gap to reliability is the difference between using these tools as toys or as trusted partners.
Let’s take a look at some of the (extremely) broad categories of companies and projects emerging and which of these problems they’re helping us solve. For clarity, these categories link back to those in our market map.

Section 2 — Who’s building solutions?
Orchestration
LLMs need to be connected to outside systems to bring in dynamic data and take actions on behalf of the user. A number of emerging tools are addressing this challenge through prompt chaining. Prompt chaining gives LLMs the ability to load data from a wide variety of sources, formulate and send additional prompts to themselves or other LLMs, and even use external APIs. By extending LLM capabilities through prompt chaining, these orchestration tools enable much more dynamic and personalized applications.
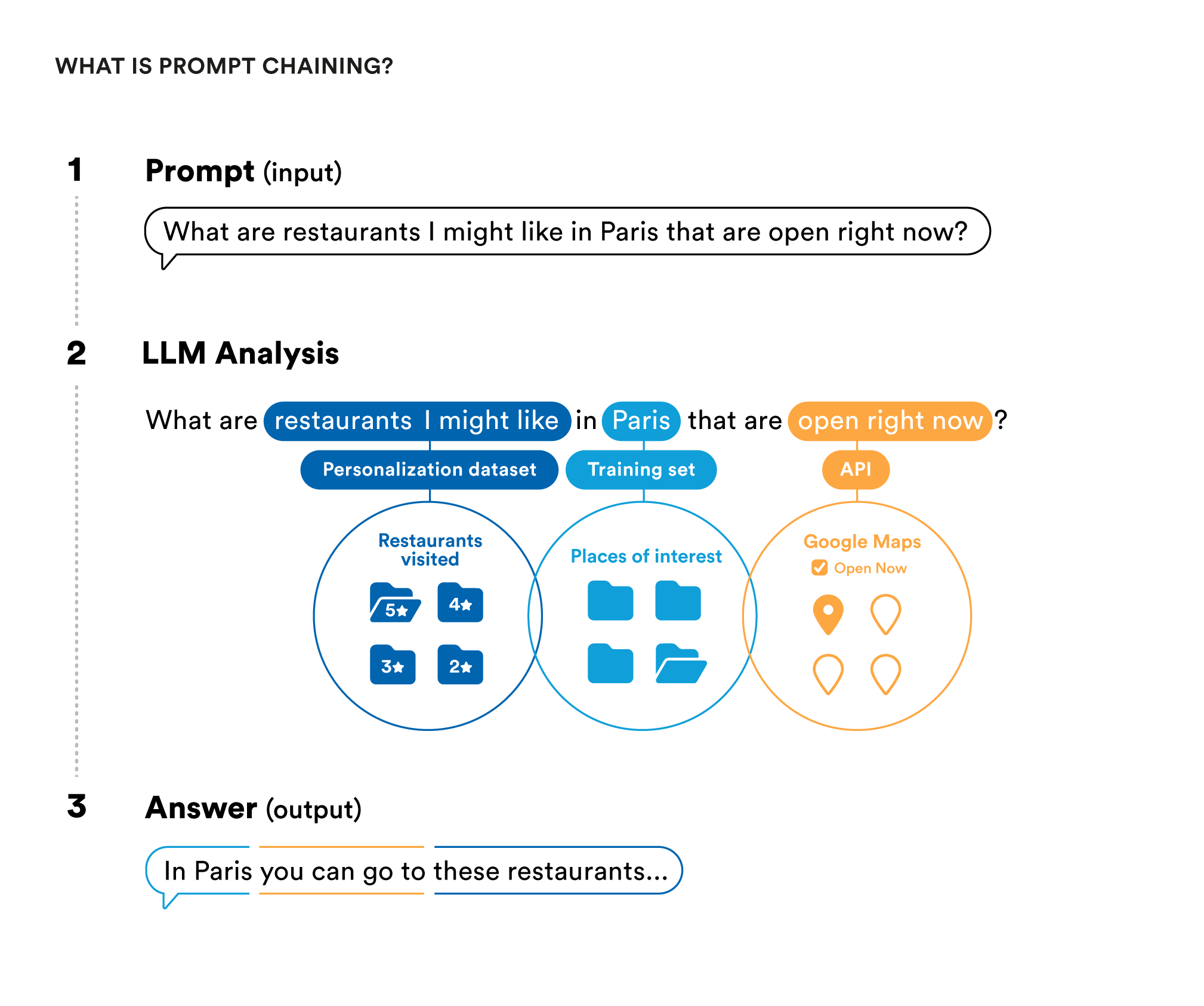
Langchain has taken the early lead as an open source framework for programming with LLMs, giving them access to other tools, and chaining prompts together. Other more structured, guided development experiences for working with LLMs are on offer from companies like Dust, re:tune, Fixie, and more.
These tools are particularly important because they are effectively the liaison between LLMs and the rest of software — multiplying the powers of each.

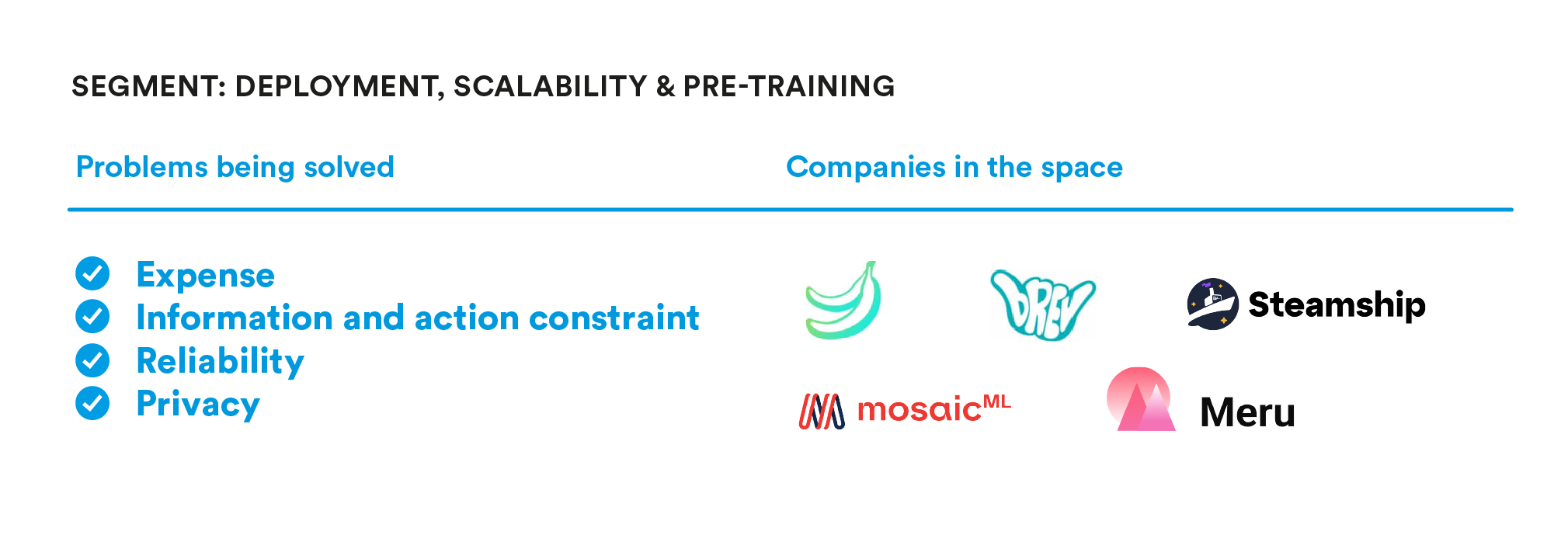
Deployment, Scalability & Pre-training
Part of the reason this AI boom is different is that new generative models have so much information encoded in them that they are fantastically proficient at a range of tasks out of the box. This makes it possible to interact with many models behind simple APIs like those for GPT-3.
Many developers find themselves working with open source, pre-trained models, which means they don’t have to worry about model training. However, these open source models create infrastructure hurdles to overcome before builders can serve their AI powered products in production. That’s why a number of solutions have emerged to abstract away the complexity of managing environments and infrastructure for this new generation of products. Beyond simply serving them well, products in this space will manipulate these models and cloud infrastructure to optimize for cost, latency, and performance.
With current technology, a smaller set of developers will choose to train their own models from scratch or using open-source architectures. We have included companies that help serve this purpose as well.
Context & Embeddings
As outlined above, LLMs often need context or data not in their original training set in order to get the right answer. LLMs solve this problem using in-context learning approaches that append a limited set of helpful information within the prompt itself at time of inference. Context & Embeddings companies focus on presenting the right content to LLMs in their context windows in a scalable, performant way.
Language models represent text as vectors of numbers (called embeddings) and these vectors can be stored in specialized vector databases optimized for data in this shape. Information stored as embeddings can be retrieved through a process called semantic search which takes a search input vector and identifies the most similar vectors in the database based on “meaning” rather than keywords. Since vector databases speak the same language of LLMs and are searchable, using them to power in-context learning has become one of the most performant ways to extend the knowledge base of an LLM and dramatically expand the range of solutions for which LLMs work “out of the box”.
Pinecone, a leading vector database company, includes a simple example on their website that demonstrates how these databases can be used to extend the capabilities of LLMs to include answering questions about information far outside of the training set, such as an internal company knowledge base. By converting the knowledge base to a set of embeddings stored in a vector database using an embedding API from OpenAI, developers enable the LLM to intake questions about the knowledge base, search the database for nearest matches, and formulate a response incorporating those matches.
In addition to loading external information, context windows have a variety of potential uses that companies are beginning to leverage. Structured prompting solutions like Guardrails can increase reliability, while prompt engineering and management solutions can increase the relevance of LLM responses. We’re even beginning to see enablement of lower cost “inference” by storing frequently asked prompt<>answer pairs.

QA & Observability
Anyone who has ever deployed a product understands the curiosity that comes with it. “How is my application performing?” “Do people like it?” “Why is it running so slowly?” There are a range of tools for answering these questions for applications built on more traditional stacks. In addition to these questions, this new generation of generative AI powered applications inspire developers to ask new questions like, “What prompts are users submitting?” “How long are our responses on average?” “What is our average latency?” “Which models are performing best?” “How should we route prompts between our models?” “Should we fine-tune?”.
A class of tools focused on generative AI applications has emerged to handle observability, monitoring, fine-tuning, QA, and other tasks for developers. These tools help developers go from a V1 of their application to V2 and beyond, and the answers these platforms surface help developers prioritize and make product tweaks. Doubtless as the products built on top of foundational models expand in complexity and footprint, these observability products will extend their capabilities as well. LLMs themselves may even have a larger role to play in the future in evaluating their own performance and the performance of other models.

Section 3 — Where is there uncertainty?
Ultimately, we are still in the early innings of the current AI development and adoption cycle. While the current challenges facing developers are fairly well defined and the potential solutions are coming into focus, there are many outstanding questions that will undoubtedly shape the ecosystem in the future.
Most notably, how and where competition occurs across the value chain for AI products, which is ultimately a large determinant of which types of companies become most valuable. In many past adoption cycles, solutions to hard problems came packaged as part of a single integrated solution rather than as a set of modular ones like the companies identified above. For this reason, foundational model companies like OpenAI pose a potential threat as they continue to strengthen their own models, expand their own tooling, and even develop their own applications. While conversely, wide availability of foundational models, interoperability of LLM systems, and a robust ecosystem of applications are all supportive of LLM enablement businesses.
In this last section, we explore how this competition is playing out at the model layer, tooling layers, and application layer. We begin with a discussion about closed vs open source foundational models before moving on to talk about competition at other points on the value chain.
Open source vs. closed source foundational models
If modular solutions are to remain competitive, the availability of quality open-sourced foundational models is likely to be critical. For businesses and founders building on top of closed source models, the flexibility they have to tailor these models to their needs across domain relevance, inference latency and cost, connectivity, and data policies is heavily dependent on the tooling capabilities made available by closed model providers.
While OpenAI open sourced GPT-2, it has not done so with GPT-3 and its variants, or GPT-4. Given the barriers created by the high cost and complexity of building cutting-edge foundational models, one can imagine a “closed” AI future where a few companies dominate the LLM space and capture an overwhelming share of the value.
That said, there is also a path for open solutions. Open source development has been a popular path for infrastructure technologies like databases, containers, mobile operating systems, and even many AI technologies like Stable Diffusion, Tensorflow, and PyTorch. As others have noted, the big tech companies are strong candidates to open source generative models in the future and Google and Meta have done so in the past. Given the high utilization of cloud services associated with generative AI applications, cloud and hardware providers are also good bets to release high quality open source tools and models. A recent example of this set of incentives operating in the wild comes from Cerebras, a cloud and hardware provider for AI applications, which recently open-sourced a family of LLMs.
Big companies aren’t the only ones providing competitive open-source models, however. Eleuther AI is a non-profit that organizes a decentralized group of researchers who coordinate primarily via Discord server. Despite lacking the warchest of the big tech players, they have released an impressive series of LLMs including GPT-J and GPT-NeoX.
As it stands today, it appears a wide array of competition will continue to exist at the foundational model layer in the form of LLMs that are strong on general language tasks, pre-trained on use case specific data, and that can be run locally.
Interoperability and lock-in
Competition is increasing in the layers of the value chain above the foundational models as well. One topic we briefly touched on is agents that connect LLMs to outside tools and enable them to take action. Recently, OpenAI entered the AI agent space when it extended ChatGPT’s capabilities with the launch of 3rd party plugins that give the chat application the ability to use external information and take action on the internet.
The launch included over a dozen plugins from Klarna, Zapier, Instacart, and others. Many hailed this as OpenAI’s app store moment. However, within a few days Langchain (featured in this piece) showed how any language model could use these plugins, and created further buzz by announcing an integration with Zapier’s Natural Language API. Zapier’s own language describing this API was decidedly agnostic as to who they partner with, which hints at how the LLM agent space will evolve.
This example speaks to the inherent interoperability of tools designed for use by one LLM with any other LLM. As long as the interaction between models and other systems or workflows occurs via natural language, lock-in will be difficult to build. While this doesn’t make it impossible to build integrated solutions in this layer, it does mean that closed model players will have a harder time building differentiated solutions while their models remain accessible via API.
Emergence of Integrated Applications
Perhaps the biggest wildcard in the competitive landscape for Generative AI is the ability of foundational model providers to become application developers themselves. By releasing ChatGPT, OpenAI became a consumer tech company overnight, threatening a subset of the applications that are built on top of GPT-3’s APIs. Character.ai and Midjourney are two other examples of companies with their own foundational models that also interface with consumers directly at the application layer.
If fully integrated applications emerge as the best way to deliver the products and experiences users demand, the ecosystem of applications built on top of these models could be crowded out and their demand for solutions that help them build AI products would shrink.
There are so many unanswered questions on these and related topics, and the answers to questions like these will determine which companies become true platforms and capture the most value in the space.

{kind=link}